
Aujourd’hui qui n’utilise pas AWS Backup pour faire ses sauvegardes ec2, RDS, Fsx etc. ? Je pense plus grand monde… Mais quid de la centralisation des rapports si vous avez plusieurs comptes AWS effectuant des sauvegardes ?
La centralisation des rapports.
Comme vous le savez sûrement, AWS Backup propose uniquement des rapports exportables sur des buckets S3 local au compte AWS. Bien évidement si vous être admin de votre organisation AWS ceci est légèrement diffèrent, mais il faut garder à l’esprit que dans de grande entreprise la donne peut être différente. En effet l’organisation peut être managé par une DSI Corp qui délègue l’administration d’une partie des comptes à ses BUs et dans ce cas pas le choix il faut ce créer ses propres outils.
Cela étant dit nous allons voir ici comment faire pour centraliser nos rapports et cerise sur le gâteau comment afficher de façon un peu plus funky l’état de nos sauvegardes.
En gros comment passer de ça :

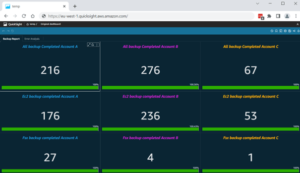
À quelque chose comme ça :
La stack technologique
Afin de mettre en place tout ceci, nous allons avoir besoin d’utiliser :
- AWS Backup Reports
- Amazon S3
- Amazon EventBridge
- AWS Lambda
- Amazon Athena
- Amazon QuickSight
- IAM
L’architecture
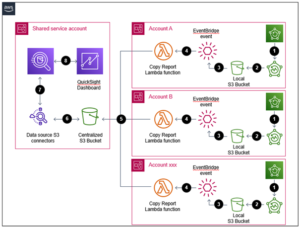
Voici le workflow de la solution :
- A la fin de la fenêtre de backup une demande de création de rapport est faite sur chaque compte AWS.
- Les rapports sont générés et envoyé sur un bucket S3 local à chaque compte AWS.
- Lors du dépôt du rapport sur le bucket un évènement EventBridge est déclenché.
- La fonction lambda s’exécute sur réception de cet évènement.
- Les rapports de chaque compte sont copie sur le bucket S3 central.
- Un connecteur S3 Athena est en place pour l’interfaçage entre Athena et le bucket contenant les rapports.
- Une table Athena est créée pour permettre à QuiskSight de l’utiliser.
- Le rapport de sauvegarde est généré et envoyé par mail chaque jour.
Mise en place de la centralisation des rapports
Dans cette première partie de cette suite d’article nous allons commencer par voir comment faire pour copier les rapports de nos X comptes AWS vers un seul et même bucket S3.
Le bucket central
Commençons par la création des buckets S3, pour cela utilisons « AWS CloudShell ».
Sur le compte central :
–bucket metanext-central-backup-reports \
–region eu-west-1 \
–create-bucket-configuration LocationConstraint=eu-west-1
aws s3api create-bucket \
--bucket metanext-central-backup-reports \
--region eu-west-1 \
--create-bucket-configuration LocationConstraint=eu-west-1
Il y a une chose très importante à savoir sur le bucket qui centralisera tous les rapports ! Il s’agit de la bucketPolicy. En effet à chaque ajout de nouveau compte AWS a la solution de centralisation il faudra venir la modifier pour ajouter l’arn du rôle d’exécution de la Lambda du nouveau compte.
La policy devrait ressembler à ceci :
« Version »: « 2012-10-17 »,
« Statement »: [
{
« Effect »: « Allow »,
« Principal »: {
« AWS »: [
« arn:aws:iam::AccountID-compteA:role/copy-backup-lambda-role »,
« arn:aws:iam::AccountID-compteB:role/copy-backup-lambda-role »
]
},
« Action »: [
« s3:PutObject »,
« s3:PutObjectAcl »
],
« Resource »: « arn:aws:s3:::metanext-central-backup-reports/* »
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::AccountID-compteA:role/copy-backup-lambda-role",
"arn:aws:iam::AccountID-compteB:role/copy-backup-lambda-role"
]
},
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::metanext-central-backup-reports/*"
}
]
}
Et maintenant si j’ajoute un compte C :
« Version »: « 2012-10-17 »,
« Statement »: [
{
« Effect »: « Allow »,
« Principal »: {
« AWS »: [
« arn:aws:iam::AccountID-compteA:role/copy-backup-lambda-role »,
« arn:aws:iam::AccountID-compteB:role/copy-backup-lambda-role »,
« arn:aws:iam::AccountID-compteC:role/copy-backup-lambda-role »
]
},
« Action »: [
« s3:PutObject »,
« s3:PutObjectAcl »
],
« Resource »: « arn:aws:s3:::metanext-central-backup-reports/* »
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::AccountID-compteA:role/copy-backup-lambda-role",
"arn:aws:iam::AccountID-compteB:role/copy-backup-lambda-role",
"arn:aws:iam::AccountID-compteC:role/copy-backup-lambda-role"
]
},
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::metanext-central-backup-reports/*"
}
]
}
Les buckets recevant les rapports
Pour la suite des opérations elles seront à faire sur chacun des comptes exécutants des backups. Il faudra juste veiller à changer les Id de vos comptes AWS.
Le bucket S3 Sur les comptes exécutant AWS Backup :
–bucket metanext-YourAccountId-local-backup-reports \
–region eu-west-1 \
–create-bucket-configuration LocationConstraint=eu-west-1aws s3api put-bucket-notification-configuration \
–bucket metanext-YourAccountId-local-backup-reports \
–region eu-west-1 \
–notification-configuration ‘{ « EventBridgeConfiguration »: {} }’
aws s3api create-bucket \
--bucket metanext-YourAccountId-local-backup-reports \
--region eu-west-1 \
--create-bucket-configuration LocationConstraint=eu-west-1
aws s3api put-bucket-notification-configuration \
--bucket metanext-YourAccountId-local-backup-reports \
--region eu-west-1 \
--notification-configuration '{ "EventBridgeConfiguration": {} }'
En plus de la création du bucket nous avons activer les notifications, ceci nous servira plus tard pour exécuter notre future Lambda automatiquement.
Les rapports
Maintenant que nous avons nos buckets nous allons passer à la génération des rapports de sauvegardes. Toujours en utilisant « AWS CloudShell » sur chacun des comptes AWS faisant des backups :
–report-plan-name Backup_reports_AccountIdA \
–report-setting ReportTemplate=BACKUP_JOB_REPORT \
–report-delivery-channel S3BucketName=metanext-YourAccountId-local-backup-reports,S3KeyPrefix=backup-reports,Formats=CSV
aws backup create-report-plan \
--report-plan-name Backup_reports_AccountIdA \
--report-setting ReportTemplate=BACKUP_JOB_REPORT \
--report-delivery-channel S3BucketName=metanext-YourAccountId-local-backup-reports,S3KeyPrefix=backup-reports,Formats=CSV
Le fait de créer un rapport va nous créer un « service-role » qu’il faudra autoriser sur le bucket S3. Nous allons donc appliquer une ‘Bucket Policy’ pour autoriser AWS Backup à copier son rapport sur le bucket précédemment créé.
Pour ce faire nous allons créer un fichier bucket_policy.json suivant que nous allons uploader sur notre environnement « CloudShell ». Le contenu sera le suivant :
« Version »: « 2012-10-17 »,
« Statement »: [
{
« Effect »: « Allow »,
« Principal »: {
« AWS »: « arn:aws:iam::YourAccountId:role/aws-service-role/reports.backup.amazonaws.com/AWSServiceRoleForBackupReports »
},
« Action »: « s3:PutObject »,
« Resource »: « arn:aws:s3:::metanext-YourAccountId-local-backup-reports/* »,
« Condition »: {
« StringEquals »: {
« s3:x-amz-acl »: « bucket-owner-full-control »
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::YourAccountId:role/aws-service-role/reports.backup.amazonaws.com/AWSServiceRoleForBackupReports"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::metanext-YourAccountId-local-backup-reports/*",
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
Et ensuite on déploie la police sur notre bucket
Le trigger Lambda
Notre bucket a précédemment été configuré pour envoyer toutes les activités de création d’objets, suppression etc. vers EventBridge, il nous faut maintenant configurer un trigger sur chaque compte afin de déclencher notre fonction de copie. Pour cela toujours avec « CloudShell » :
–name « start_lambda_report_copy » \
–event-pattern « {\ »source\ »:[\ »aws.s3\ »],\ »detail-type\ »:[\ »Object Created\ »],\ »detail\ »:{\ »bucket\ »:{\ »name\ »:[\ »metanext-YourAccountId-local-backup-reports\ »]},\ »object\ »:{\ »key\ »:[{\ »prefix\ »:\ »backup-reports\ »}]}}} »
aws events put-rule \
--name "start_lambda_report_copy" \
--event-pattern "{\"source\":[\"aws.s3\"],\"detail-type\":[\"Object Created\"],\"detail\":{\"bucket\":{\"name\":[\"metanext-YourAccountId-local-backup-reports\"]},\"object\":{\"key\":[{\"prefix\":\"backup-reports\"}]}}}"
Dans le retour de l’exécution de la commande il faut bien noter l’ARN de votre rôle, nous allons en avoir besoin un peu plus tard.
La Lambda
Place au déploiement de la fonction de copie des rapports locaux vers le bucket centralisé.
Avant de parler du déploiement je vous conseille de prendre le code suivant, de le mettre dans un fichier « lambda_function.py » et de zipper le tout. Bien évidement il ne faudra pas oublier de l’uploader sur votre environnement « Cloudshell » :
import boto3
import datetime
import logging
import os
import time#Logs
FORMAT = « Level:%(levelname)s – Line:%(lineno)d – Function:%(funcName)s – %(message)s »
logger = logging.getLogger()
for h in logger.handlers:
h.setFormatter(logging.Formatter(FORMAT))
logger.setLevel(logging.INFO)def lambda_handler(event, context):try:
logger.info(« Starting Process »)
sts= boto3.client(« sts »)#Getting source info from event
source_bucket = event[‘detail’][‘bucket’][‘name’]
logger.info(‘source_bucket: %s’,source_bucket)
source_key = event[‘detail’][‘object’][‘key’]
logger.info(‘source_key: %s’,source_key)#Copy object to different bucket
s3_resource = boto3.resource(‘s3’)
copy_source = {
‘Bucket’: source_bucket,
‘Key’: source_key
}
account_id = sts.get_caller_identity()[« Account »]
#Building destination key
target_key = source_key
logger.info(‘target_key %s’,target_key)
#ACL to give rights to destination account on the S3 object, if not source account will be remain the owner
logger.info(‘Copy action to %s’,os.environ[‘destination_bucket’])
s3_resource.Bucket(os.environ[‘destination_bucket’]).Object(target_key).copy(copy_source, ExtraArgs={‘ACL’: ‘bucket-owner-full-control’})
logger.info(« End Process »)
except:
raise
import json
import boto3
import datetime
import logging
import os
import time
#Logs
FORMAT = "Level:%(levelname)s - Line:%(lineno)d - Function:%(funcName)s - %(message)s"
logger = logging.getLogger()
for h in logger.handlers:
h.setFormatter(logging.Formatter(FORMAT))
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
try:
logger.info("Starting Process")
sts= boto3.client("sts")
#Getting source info from event
source_bucket = event['detail']['bucket']['name']
logger.info('source_bucket: %s',source_bucket)
source_key = event['detail']['object']['key']
logger.info('source_key: %s',source_key)
#Copy object to different bucket
s3_resource = boto3.resource('s3')
copy_source = {
'Bucket': source_bucket,
'Key': source_key
}
account_id = sts.get_caller_identity()["Account"]
#Building destination key
target_key = source_key
logger.info('target_key %s',target_key)
#ACL to give rights to destination account on the S3 object, if not source account will be remain the owner
logger.info('Copy action to %s',os.environ['destination_bucket'])
s3_resource.Bucket(os.environ['destination_bucket']).Object(target_key).copy(copy_source, ExtraArgs={'ACL': 'bucket-owner-full-control'})
logger.info("End Process")
except:
raise
Il nous faut maintenant créer le rôle d’exécution de la Lambda. Ce rôle va également devoir avoir des droits pour aller écrire sur notre bucket centralisé.
On prend la ‘relation d’approbation’ suivante pour la mettre dans un fichier « lambda_trust_relationships.json » et on l’upload directement sur notre environnement « CloudShell »:
« Version »: « 2012-10-17 »,
« Statement »: [
{
« Effect »: « Allow »,
« Principal »: {
« Service »: « lambda.amazonaws.com »
},
« Action »: « sts:AssumeRole »
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Nous allons également créer un deuxième fichier JSON (lambda_excution_right.json) que nous allons également uploader sur notre « CloudShell ». Ce rôle va nous permettre d’affecter des droits a note rôle :
« Version »: « 2012-10-17 »,
« Statement »: [
{
« Effect »: « Allow »,
« Action »: « s3:GetObject »,
« Resource »: « arn:aws:s3:::NOM-DU-BUCKET-SOURCE/* »
},
{
« Effect »: « Allow »,
« Action »: [
« s3:PutObject »,
« s3:PutObjectAcl »
],
« Resource »: « arn:aws:s3:::NOM-DU-BUCKET-CENTRAL/* »
},
{
« Effect »: « Allow »,
« Action »: [
« logs:CreateLogGroup »,
« logs:CreateLogStream »,
« logs:PutLogEvents »
],
« Resource »: « * »
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::NOM-DU-BUCKET-SOURCE/*"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::NOM-DU-BUCKET-CENTRAL/*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
Maintenant la création du rôle :
–role-name « copy-backup-lambda-role » \
–assume-role-policy-document file://lambda_trust_relationships.json
aws iam create-role \
--role-name "copy-backup-lambda-role" \
--assume-role-policy-document file://lambda_trust_relationships.json
Dans le retour de l’exécution de la commande il faut bien noter l’ARN de votre rôle, nous allons en avoir besoin juste après.
Sans droit ce rôle n’a pas grande utilité du coup nous allons lui donner le droit d’aller lire/écrire sur nos buckets et également lui donner des droits sur Cloudwatch.
Création de la police :
–policy-name copy-backup-lambda-policy \
–policy-document file://lambda_excution_right.json
aws iam create-policy \
--policy-name copy-backup-lambda-policy \
--policy-document file://lambda_excution_right.json
Dans le retour de l’exécution de la commande il faut bien noter l’ARN de votre police, nous allons en avoir besoin juste après.
Affectation de la police a notre rôle :
–policy-arn ARN-DE-VOTRE-POLICY \
–role-name copy-backup-lambda-role
aws iam attach-role-policy \
--policy-arn ARN-DE-VOTRE-POLICY \
--role-name copy-backup-lambda-role
Maintenant que notre rôle d’exécution est créé et que notre code a été poussé sur « CloudShell » nous allons pourvoir déployer la Lambda :
–function-name copy-backup-lambda \
–runtime python3.9 \
–timeout 60 –memory-size 128 \
–environment Variables= »{file_name=backup_job_report.csv,destination_bucket=VOTRE-BUCKET-CENTRAL} » \
–zip-file fileb://lambda_function.zip \
–handler lambda_function.lambda_handler\
–role ARN-ROLE-EXECUTION-LAMBDA
aws lambda create-function \
--function-name copy-backup-lambda \
--runtime python3.9 \
--timeout 60 --memory-size 128 \
--environment Variables="{file_name=backup_job_report.csv,destination_bucket=VOTRE-BUCKET-CENTRAL}" \
--zip-file fileb://lambda_function.zip \
--handler lambda_function.lambda_handler\
--role ARN-ROLE-EXECUTION-LAMBDA
Dans le retour de l’exécution de la commande il faut bien noter l’ARN de votre lambda, nous allons en avoir besoin juste après.
On passe à l’ajout d’un trigger pour que notre Lambda s’exécute à chaque fois qu’un nouveau rapport de sauvegarde est disponible et ainsi copie le nouveau rapport sur le bucket central :
–function-name copy-backup-lambda \
–statement-id start_lambda_report_copy \
–action ‘lambda:InvokeFunction’ \
–principal events.amazonaws.com \
–source-arn ARN-EVENT-CLOUDWATCHaws events put-targets \
–rule start_lambda_report_copy \
–targets « Id »= »1″, »Arn »= » ARN-DE-VOTRE-LAMBDA »
aws lambda add-permission \
--function-name copy-backup-lambda \
--statement-id start_lambda_report_copy \
--action 'lambda:InvokeFunction' \
--principal events.amazonaws.com \
--source-arn ARN-EVENT-CLOUDWATCH
aws events put-targets \
--rule start_lambda_report_copy \
--targets "Id"="1","Arn"=" ARN-DE-VOTRE-LAMBDA"
Conclusion
Voilà le déploiement de la première partie est finalisé. Si vous avez suivi toutes les étapes correctement vous devriez voir apparaitre à chaque nouveau rapport de sauvegarde un copie dans de ce rapport dans le bucket central.
Pour le tester rien de plus simple il suffit de générer un rapport via AWS Backup.
Si je résumé nous avons :
- Créé un bucket central pour recevoir l’intégralité des rapports de sauvegarde.
- Créé un lambda pour gérer la copie des rapports de sauvegarde.
- Manipuler des Rôles et Police IAM
- Gérer des Droits d’accès aux différents bucket.
- Et le plus important CENTRALISE NOS RAPPORTS…
En attendant le deuxième épisode qui portera sur l’intégration avec AWS Athena je vous souhaite une agréable journée et surtout si vous avez des questions n’hésitez pas nous serons ravis d’y répondre.
Frédéric CHAMPAGNE, Tribu Leader AWS