
Si le calcul parallèle et les algorithmes ont connu des progrès importants, les technologies de stockage et de transfert du Big Data s’appuient essentiellement sur des technologies traditionnelles conçues à l’époque du traitement en série.
L’heure est au Big Data en temps réel !
Seul un nouveau type de système de stockage peut fournir les volumes massifs de données nécessaires à ces nouveaux modèles informatiques. C’est pour répondre à cet enjeu que Pure Storage à développer la Stratégie Data Hub afin de permettre de regrouper et de traiter en temps réel sur une même infrastructure l’ensemble des données et en finir avec les silos
Une démo pour illustrer la proposition de valeur
Pure Storage a demandé à Metanext de participer activement au déploiement d’une démonstration avec une plateforme Big Data / Machine Learning sur la solution de stockage Pure Storage FlashBlade, pour illustrer le traitement temps réel de flux de données.
Une solution Big Data / Machine Learning basée sur l’écosystème Hortonworks
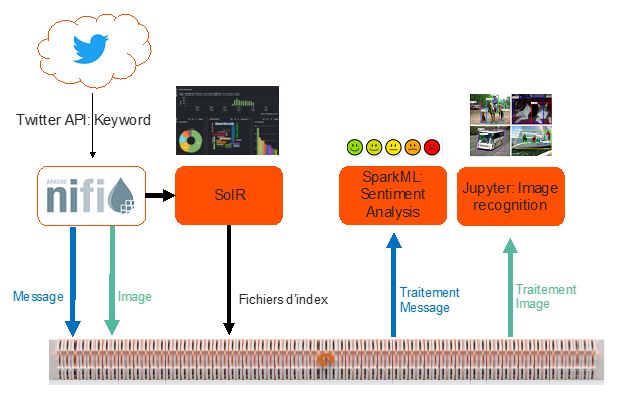
La solution implémentée s’appuie sur de nombreux composants de la plateforme Hortonworks Data Platform (HDP) et Hortonworks Data Flow (HDF) notamment NiFi, Solr, Spark et Zeppelin. De même, des bibliothèques de la communauté Open Source ont été utilisées.
Nifi S3 SolR Zeppelin Spark CoreNLP

L’analyse de bout en bout et en continu de données Twitter
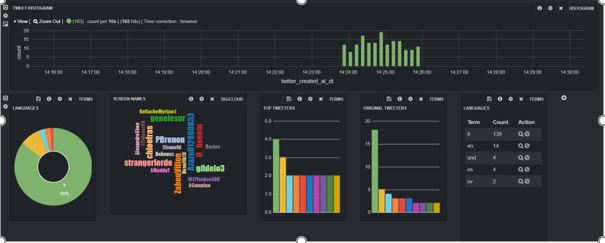
Le premier scénario mis en œuvre fournit une solution de bout en bout pour l’analyse des sentiments sur des données collectées en continu sur Twitter.
Dans un premier temps, la plateforme Hortonworks, avec ses différents services comme apache NiF, a été installée et configurée.
Un template Nifi (ou NiFi Flow) est utilisé pour collecter les flux depuis Twitter, en se basant sur l’API publique Twitter, puis pour les indexer dans Apache Solr. Les tweets stockés dans Apache Solr sont traités par Apache Spark puis sont visualisés à l’aide de tableaux de bord Banana. Les fonctions de la bibliothèque Stanford CoreNLP ont été intégrées dans Spark pour supporter l’analyse des sentiments du texte des tweets.
La détection d’objets sur les images
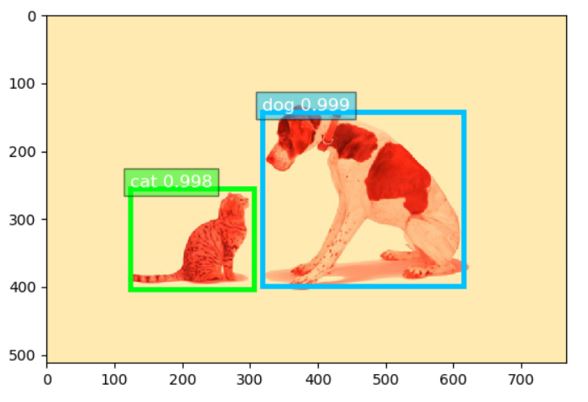
Pour le second scénario, la même plateforme a été mise à contribution pour la détection d’objets sur les images. Pour ce faire, des « processeurs » ont été rajoutés dans Nifi Flow pour stocker les tweets contenant des images dans des buckets S3 hébergés sur FlashBlade.
Pour finir, un environnement Data Science contenant les différents outils (Python, JupyterHub, Machine Learning frameworks, Deep Learning frameworks …) a été installé et configuré. Le framework de Deep Learning Apache mxnet a été déployé en utilisant un modèle pré-entraîné (YOLOv3) pour la détection des objets. Ceci permet très simplement de traiter les images stockées dans les buckets S3, pour, dans le cas de ce démonstrateur, détecter les objets présents dans les images.
Une plate-forme haute-performance idéale pour le temps réel
En synthèse, ce démonstrateur illustre la stratégie de Pure Storage sur le Data Hub, dont l’objectif est de pouvoir appliquer des chaines de traitement sur les flux de données en temps réel, en s’appuyant sur une plateforme simple, performante et évolutive.
Flash Blade
D’un point de vue fonctionnel, ces technologies peuvent être utilisées dans le cadre de nombreux projets d’analyse de données, notamment pour le traitement de médias riches (images, audio, vidéo), qui deviennent de plus en plus des standards de communication.


