La data, une ressource très précieuse !
C’est la raison pour laquelle les grandes compagnies génèrent et traitent un volume aussi important de données afin de répondre aux besoins des clients.
Une arme à double tranchant, car cela implique des défis (ex : la performance du traitement ou la haute disponibilité des données) et impose la prise de décisions stratégiques (ex : passage au cloud).
Le besoin de migrer
Migrer certes, mais de quoi vers quoi ?
Qu’il s’agisse de passer d’On-Premise vers le cloud; du cloud vers le cloud; ou vers le multi-cloud, avoir une stratégie de migration est essentiel pour répondre d’une manière efficace à la croissance du business.
Automatiser la migration
Automatiser la migration fait partie des objectifs de l’équipe Data & Analytics. Cela va permettre de gérer le processus en tant que service qui fera partie du Digital Service Market de l’entreprise, un outil de bout en bout pour :
- Sauvegarder et restaurer les bases de données d’un environnement (ex : Production) vers un autre (ex : Développement).
- Migrer les données d’une plateforme (ex : Openstack) vers une autre (ex : GCP)
Derrière les coulisses
Comme vous l’avez surement déjà constaté, le besoin est simple et clair à décrire. C’est pourquoi la première idée qui traverse l’esprit est de trouver ou bâtir cet outil magique qui serait capable de tout faire.
Cependant, cela se heurte à des contraintes de sécurité liées par exemple aux flux de données autorisés inter-cloud. Et même si c’était le cas, ce n’est pas un bon choix d’architecture compte tenu de la complexité et la maintenabilité du projet.
Vue d’architecture
Diviser pour mieux régner, un projet spécifique à chaque fournisseur de cloud.
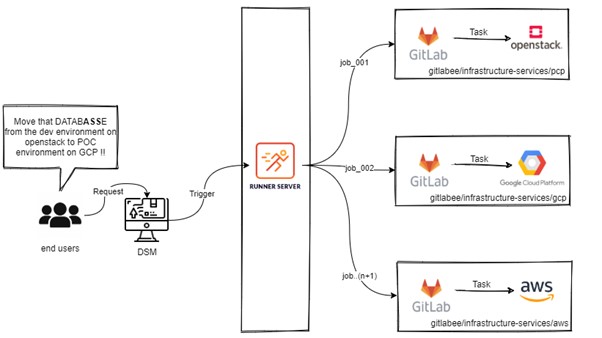
La feuille de route
Avant même d’envisager la migration des bases de données inter-cloud, on doit pouvoir le faire inter-environnements (POC, Dev, Re7 et Prod), puis faire le lien entre :
- Un service / fournisseur de cloud : La sauvegarde ainsi que la restauration des DBs inter-environnement.
- Un service qui va jouer le rôle d’un routeur inter-cloud.
Un choix qui favorise à la fois la livraison et le feedback client. En effet, il est nécessaire d’avoir un premier retour d’expérience d’un point de vue technique et fonctionnel afin de mieux adapter l’outil tout au long de l’évolution.
Google Cloud Platform, La priorité
On doit commencer par mettre en place le service de migration inter-environnements sur GCP en premier lieu pour répondre à la demande de nos clients.
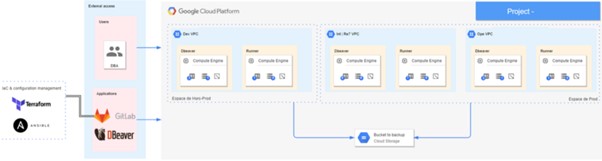
Le projet
La partie Infrastructure as Code ainsi que la partie Configuration Management sont représentés par les répertoires suivants :
- gcp-project/terraform.
- gcp-project/ansible.
Le flux entre la création de l’infrastructure et la migration inter-environnements d’une base de données est orchestré par un pipeline gitlab-CI.
Infrastructure as Code avec Terraform
La partie Terraform a pour rôle de monter l’infrastructure nécessaire pour effectuer une migration de base de données. Pour être plus précis, cela consiste en :
- gcp-project/terraform/01-instances: la création d’une VM (Runner) à travers laquelle nous allons jouer nos rôles (scripts) Ansible.
- gcp-project/terraform/02-storage: la création d’un bucket GCP partagé entre les différents environnements.
Configuration Management avec Ansible
La partie Ansible vise à définir les actions à réaliser à travers un ensemble de scripts (rôles Ansible) qui partagent le même contexte:
- gcp-project/ansible/roles/rn-db-export: export d’une base de données d’un environnement source vers le bucket GCP, le dump.
- gcp-project/ansible/roles/rn-db-import: import d’une base de données à partir du bucket GCP vers l’environnement cible, la restauration.
- gcp-project/ansible/roles/rn-db-import-export-common: un rôle qui regroupe les actions en commun ainsi que les prérequis (ex : la validation des inputs et des règles, la consultation de vault).
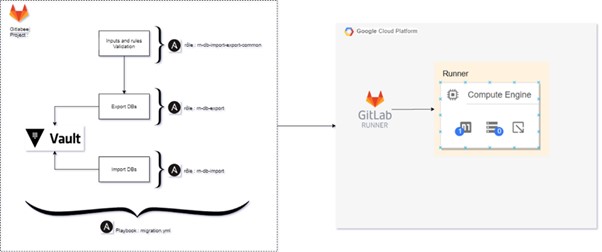
GCP — Flux de la partie Configuration Management
Le bout de tunnel
Le client saisit sa demande à travers le service avec les différentes entrées (ex : source env, base de données, target env, service id). Une fois validé, le pipeline gitlab-ci se chargera de tout le processus de migration.
En conclusion
Automatiser un process de migration de bases de données nous a permis de :
- Rendre le temps d’arrêt de service proche de zéro, avec notamment la migration à chaud.
- Avoir un feedback continu, à travers les webhooks de teams.
- Exploiter les services managés DMS (Database Migration Services) des fournisseurs de cloud.
par Safwene BEN AICH
