
Il y a un an, Amazon Web Services, AWS, a fait une annonce qui m’a enthousiasmé : la possibilité d’exécuter des fonctions Lambda sur leur processeur Graviton basé sur une architecture ARM.
Pourquoi cette annonce était enthousiasmante ?
Principalement pour deux raisons :
La première est que Graviton est plus performant qu’un équivalent x86. En conséquence, à configuration identique, une Lambda s’exécutera plus rapidement sur Graviton que sur x86. Et comme AWS facture au « GB-seconds », c’est tout bon pour le portefeuille !
La deuxième raison est que les architectures ARM que l’on retrouve massivement dans nos téléphones mobiles sont nettement moins énergivores que les architectures x86. Et ça, c’est tout bon pour la planète !
En résumé, on aurait tort de se priver.
À l’occasion du premier anniversaire de cette annonce, je vous propose mon retour d’expérience de la migration de centaines de Lambdas personnelles vers Graviton.
C’était quoi le plan ?
En réalité, pas très compliqué. Pourquoi ?
Parce que toutes mes Lambdas sont déployées par des pipelines CI/CD qui utilisent, tous, le même module Terraform que j’ai nommé « aws-lambda ». Ok, pas très original mais on devine assez bien à quoi peut servir ce module.
Celui-ci, je l’avais préparé aux petits oignons avec, entre autres, durée de rétention de logs, versioning, alias d’environnements, filtres pour notifications et quelques épices mais cela est une autre histoire.
Du coup, la migration fut assez simple puisqu’il a suffi d’ajouter une ligne au « main.tf » du module « aws-lambda » :
architectures = var.architecture
et ajouter une variable dans le « variables.tf » de « aws-lambda » :
variable "architecture" {
type = list(string)
default = ["arm64"]
description = "Lambda instruction set architecture"
}
En spécifiant « arm64 » comme valeur par défaut, j’inverse le comportement originel des APIs AWS qui utilisent « x86_64 » comme valeur par défaut. Ainsi, je n’ai pas besoin de repasser sur la définition de chacune des centaines de Lambdas qui constituent mon parc applicatif et cela satisfait pleinement le fainéant qui sommeille en moi, forcément.
En relançant les pipelines CI/CD, toutes les Lambdas ont pu être migrées en quelques minutes. Cool.
Maintenant, vous vous doutez que la migration n’a pas modifié les Lambdas de « production » mais celles qui se trouvaient dans des environnements de « tests » pour justement être testées. Malinx, le lynx.
Globalement, les tests furent positifs. Ce n’est pas très étonnant car toutes les Lambdas sont écrites en Python qui est un langage interprété. Comme on peut faire confiance à AWS pour la portabilité du « runtime » de x86 à ARM, il n’y avait finalement aucune raison pour que cela ne fonctionne pas.
Sauf que, évidemment, tout n’a pas fonctionné ! Les emm… ennuis commencent.
Environ 5% des Lambdas migrées se plantent avec des messages d’erreurs hétérogènes.
Rapidement, je me rends compte que les Lambdas dysfonctionnantes (j’aime inventer des mots) utilisent toutes des dépendances externes au « runtime » de base mais ce n’est pas discriminant. En effet, de nombreuses autres Lambdas migrées dépendent également de modules externes mais fonctionnent correctement.
Je plonge alors inspecter plus profondément ces dépendances externes dysfonctionnantes. Je découvre que celles-ci, écrites en Python, utilisent des librairies compilées écrites en C alors que les dépendances qui fonctionnent correctement ne contiennent que du script Python. Ces librairies compilées sont, par exemple, un parser XML ou un transcodeur JPEG/PNG.
Les pipelines CI/CD
Avant d’aller plus loin, je dois vous décrire mes pipelines CI/CD.
Le code de source de mes projets perso est hébergé chez Gitlab en mode SaaS. Dans cette configuration, un simple fichier YAML à la racine du repo et décrivant les différentes tâches d’un pipeline permet d’exécuter celui-ci manuellement ou automatiquement lors d’un commit par exemple.
Tous mes projets disposent d’un fichier « .gitlab-ci.yml » à leur racine.
Chaque tâche d’un pipeline Gitlab est exécutée dans un « Runner ». Même si elle n’est pas très précise sur la question, il semblerait que la documentation Gitlab indique qu’en mode SaaS seuls des « Runners » sous architecture x86 soient disponibles.
En conséquence, si une tâche contient la commande suivante :
pip install lxml
Le « Runner » récupérera les dépendances de ce parser XML pour une architecture x86.
Je tenais donc ma root cause : des composants de certains packages de déploiement contiennent des fichiers compilés avec un jeu d’instructions différent de celui dans lequel ils seront exécutés !
Très bien, mais on fait quoi maintenant ?
Le premier réflexe est de chercher une autre solution de CI/CD compatible avec ARM. Mais rapidement je me dis que refaire des pipelines pour quelques dizaines de projets alors que seuls 2 sont directement concernés, c’est un peu too much. Et comme la dispersion de pipelines n’est pas envisageable, j’abandonne cette recherche.
Comme j’ai décidé de rester dans Gitlab, la deuxième idée qui arrive c’est de développer un « Runner » compatible ARM comme ici. Puis l’héberger (sur mon Raspberry Pi ?) et le maintenir. Bof, pas très compatible avec mon mindset « Serverless ».
Arrive alors la troisième idée que j’espère être la bonne. Il s’agit d’un mix entre les 2 premières puisque je vais conserver les pipelines Gitlab mais externaliser uniquement la tâche de « build » puisque c’est elle qui pèche. L’avantage est que je n’aurai que les pipelines des projets impactés à modifier sans avoir à maintenir une infrastructure complémentaire.
Ça, ce fut rapide. En effet, l’objectif originel étant de déployer des Lambdas, « AWS CodeBuild » est rapidement apparu comme le service pouvant répondre au besoin.
La transformation des pipelines « dysfonctionnants » a été amusante car elle a été faite à la mode « Inception ». J’ai dû définir des tâches qui créent des gestionnaires de tâches externes, puis des tâches qui lancent des tâches externes. Vous l’avez ?
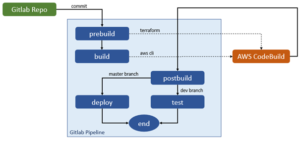
Build, Test, Deploy
Présenté autrement et très schématiquement, les pipelines originels sont constitués de 3 phases : « build », « test » et « deploy »
La phase « build » construit les packages de code à partir des scripts Python et de leurs dépendances.
La phase « test » déploie les fonctions Lambda à l’aide de Terraform et des packages buildés dans des environnements de tests.
La phase « deploy » déploie les fonctions Lambda dans l’environnement de production.
La remédiation des pipelines « dysfonctionnants » a constitué à éclater la phase « build » en trois phases : « prebuild », « build » et « postbuild »
La phase « prebuild » crée ou met à jour un projet AWS CodeBuild à l’aide de Terraform
La phase « build » lance l’exécution du projet CodeBuild avec les paramètres du commit courant
La phase « postbuild » récupère les artefacts générés par CodeBuild pour les ré-injecter dans le pipeline Gitlab
La partie un peu « tricky » de cette histoire fut le chainage retour de CodeBuild. En effet, le « start-build » est asynchrone, et c’est logique. Cependant, il n’est alors pas possible d’« attendre » la fin de son exécution. Il fallait donc que CodeBuild « retourne » de lui-même dans le pipeline Gitlab qui devait alors prendre un autre chemin que celui emprunté par un commit.
Pour m’orienter dans le pipeline, j’utilise la variable d’environnement $CI_PIPELINE_SOURCE
Voici un extrait de « .gitlab-ci.yml »
prebuild: stage: prebuild image: registry.gitlab.com/cannereau/terraform:latest rules: - if: $CI_PIPELINE_SOURCE != "trigger" script: - cd build - export TF_VAR_EDITOR=$GITLAB_USER_EMAIL - terraform init - terraform apply -auto-approve build: stage: build image: registry.gitlab.com/gitlab-org/cloud-deploy/aws-base:latest rules: - if: $CI_PIPELINE_SOURCE != "trigger" script: - aws codebuild start-build --project-name my-project --environment-variables-override name=GITLAB_BRANCH,value=$CI_COMMIT_REF_NAME name=GITLAB_COMMIT,value=$CI_COMMIT_SHORT_SHA postbuild: stage: postbuild image: registry.gitlab.com/gitlab-org/cloud-deploy/aws-base:latest rules: - if: $CI_PIPELINE_SOURCE == "trigger" script: - ART="s3://my.bucket.com/artifacts/my-project" - aws s3 mv --no-progress "$ART/$CI_COMMIT_REF_NAME/$CI_COMMIT_SHORT_SHA/package.zip" "package.zip" artifacts: paths: - package.zip
Pour « retourner » dans le pipeline à partir de CodeBuild, je vais utiliser un « trigger token » qui permet de déclencher des pipelines Gitlab depuis l’extérieur.
Le projet CodeBuild est donc constitué de 4 phases :
La phase « install » est en charge de mettre à niveau le runtime avec une version compatible avec le code source des Lambdas
La phase « pre_build » récupère le code source en clonant le repo Gitlab
La phase « build » télécharge les dépendances et construit le package avec le code source. Les dépendances sont ici bien compatibles avec ARM puisqu’on aura correctement configuré le worker dans « codebuild.tf » :
compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/amazonlinux2-aarch64-standard:2.0" type = "ARM_CONTAINER"
La phase « post_build » stocke les artefacts dans un bucket S3 et « retourne » dans le pipeline Gitlab
Voici le « buildspec.yml » qui détaille tout cela :
version: 0.2
env:
parameter-store:
GITLAB_PAT: "/gitlab/pat"
GITLAB_USERNAME: "/gitlab/username"
GITLAB_TRIGGER: "/gitlab/trigger/my-project"
phases:
install:
runtime-versions:
python: 3.9
pre_build:
commands:
- GITLAB="https://$GITLAB_USERNAME:$GITLAB_PAT@gitlab.com"
- git clone "$GITLAB/cannereau/my-project.git"
- cd my-project
- git switch $GITLAB_BRANCH
build:
commands:
- python --version
- pip install --target=code lxml
- find code -exec touch -t 202002020000 {} +
- cd code
- zip -qrX package.zip handler.py lxml
post_build:
commands:
- ART='s3://my.bucket.com/artifacts/my-project'
- aws s3 cp --no-progress package.zip
"$ART/$GITLAB_BRANCH/$GITLAB_COMMIT/package.zip"
- curl -X POST –fail
-F token=$GITLAB_TRIGGER
-F ref=$GITLAB_BRANCH
-s https://gitlab.com/api/v4/projects/15261719/trigger/pipeline
> trigger.json
- cat trigger.json | jq '.'
Vous noterez au passage que j’utilise le « Parameter Store AWS » pour stocker les tokens nécessaires à CodeBuild pour communiquer avec Gitlab
Et Bingo !
Tous mes pipelines Gitlab déploient maintenant des fonctions Lambdas ARM complètement fonctionnelles.
Comme je le disais au début de l’article : il n’y a plus aucune raison de s’en priver !
Sauf que… Si, il en reste une.
A ce jour, les infrastructures ARM ne sont pas globalement déployées chez AWS. Paris (eu-west-3) n’en dispose pas, par exemple. C’est fort probablement pour cette raison d’ailleurs que Lambda@Edge n’est disponible qu’en x86 et, vous l’aurez compris, mes dernières Lambdas qui attendent leur passage ARM sont des Lambda@Edge.
Quoiqu’il en soit, n’hésitez pas à explorer des solutions de compute ARM, elles valent le coup. Et si vous rencontrez un obstacle, sautez-le ou contourner-le, mais passez-le !
Bon voyage dans le Cloud 😊
– Christophe ANNEREAU, Consultant Cloud & Tribu Leader