
Tout pour la donnée !
La donnée est devenue le centre du monde et le nouvel Eldorado ! Tout est fait pour accumuler autant de données que possible, sur tout, afin de trouver un jour la fameuse pépite qui fournira l’avantage concurrentiel décisif.
Encore faut-il pouvoir la stocker, la retrouver, la qualifier, la traiter, la restituer, la chiffrer ! Et surtout pas la perdre, ou encore pire se la faire voler.
Cette course folle explique en grande partie l’évolution majeure des technologies de stockage depuis une dizaine d’années – et ce n’est pas fini ! – afin d’apporter des réponses à ces nouveaux enjeux.
Alors j’ai eu l’idée de rédiger ce « Vademecum » (à mon âge, j’adore utiliser des termes désuets, cela me rajeunit !), en 2 parties, sur le stockage pour faire un tour d’horizon rapide mais tout de même complet, enfin je l’espère, du marché et des tendances.
Une sorte d’aide-mémoire (bonjour le poisson rouge …) ou de boîte à outils afin d’avoir à l’esprit le moment venu l’historique, les tendances, les mots-clés, les enjeux, les principes, les questions, …
En espérant que cela vous soit utile.
Et pour les amoureux du stockage, j’en profite pour vous recommander le PodCast « Unleash your storage passion » http://www.podcast.unleash-your-storage-passion.fr/
Et maintenant, c’est parti pour la première partie !
Stockage Flash
A tout seigneur, tout honneur ! Si je devais identifier l’évolution majeure du stockage depuis 10 ans, ce serait clairement l’avènement du stockage flash qui a totalement bouleversé le rôle du stockage dans l’infrastructure à cause de l’énorme gain en performance.
A ce titre, un petit retour sur son histoire est le bienvenu car cela permet de remettre en perspective les atouts mais aussi les contraintes, et de bien comprendre les impacts et les conséquences sur les autres composants.
Mais aujourd’hui où en sommes-nous avec les SLC, MLC, TLC et QLC ??? Voici un tableau de synthèse pour mieux s’y retrouver.
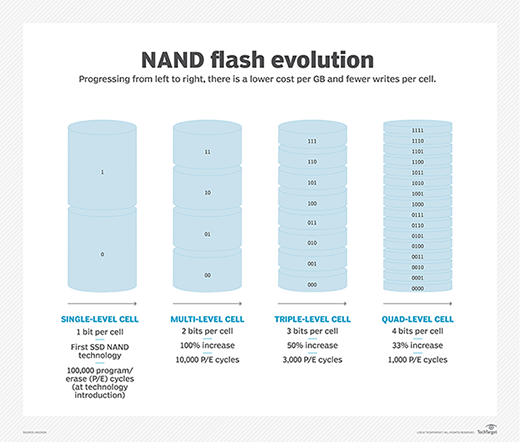
Et pour en savoir encore un peu plus sur ces différentes technologies, alors cet article est fait pour vous : https://searchstorage.techtarget.com/tip/Flash-memory-standards-and-interfaces-every-IT-admin-should-know
NVMe
Une autre (r)évolution majeure est l’arrivée et l’adoption du NVMe. Avec un stockage Flash toujours plus performant (et je n’ai pas encore parlé de SCM …), les protocoles de transfert de données comme le standard SCSI devaient évoluer drastiquement afin de s’adapter aux performances des disques.
NVMe (depuis 2011 !) apporte une réponse pertinente, notamment avec des capacités de parallélisation très importantes (64000 files d’attente avec chacune 64000 commandes !) et un jeu de commandes simplifié pour réduire la charge de travail du processeur et améliorer la latence.
Accouplé à un connecteur PCIe, les disques SSD NVMe vont peu à peu, dans les prochaines années, remplacer les disques SSD SATA et SAS en tant que disque Flash « standard » dans les serveurs et dans les baies de stockage.
Dans un premier temps, le NVMe a été aussi synonyme de « bras armé » pour la prise de pouvoir du stockage local au sein des serveurs (notamment pour l’approche SDS et les solutions hyperconvergentes) au détriment du stockage partagé, grâce à ses performances exceptionnelles.
Finalement, avec l’arrivée des protocoles de la famille NVMe over Fabrics, le stockage partagé est toujours (bien) présent, et les constructeurs l’ont tous adopté et déployé au sein de leurs gammes.
La spécification NVMe-Of utilisant l’accès direct à la mémoire à distance (RDMA, Remote Direct Memory Access) via Ethernet (RoCE, RDMA over Converged Ethernet) ou Infiniband permet de minimiser au maximum l’impact du réseau sur le temps de réponse, avec des accès presque aussi rapides qu’en local. En revanche, cela impose de mettre en place des équipements et des configurations spécifiques.
Dans le monde « traditionnel » FC ou IP, cela pose un problème majeur en rapport avec les compétences en place et surtout les investissements lourds déjà réalisés.
Ceci a été résolu avec les protocoles NVMe-oF over FC (FC-NVMe) et NVMe over TCP (NVMe/TCP).
En effet, FC-NVMe et FC Gen 5/6 coexistent dans une même infrastructure (HBA et commutateurs/directeurs), ce qui permet d’éviter une mise à niveau de grande ampleur.
De son côté, NVMe/TCP, présente la particularité d’embarquer les commandes NVMe dans des paquets TCP/IP tout ce qu’il y a de plus standard. NVMe/TCP se présente donc comme l’une des solutions les plus économiques, puisque les infrastructures Ethernet sont moins chères que celles en Fiber Channel utilisées en NVMe-over-FC, et plus simple à mettre en oeuvre, d’autant que les réseaux TCP/IP sont largement maîtrisés chez les clients.
Par conséquent, il est possible de bénéficier des gains de performance procurés par le NVMe pour les besoins du Métier, avec son infrastructure de stockage partagé, sans repartir d’une feuille blanche ou presque.
Et le stockage partagé reste un thème particulièrement important pour les clients comme le montre l’étude menée par le cabinet Codalgo Research en mars 2020 auprès de 1500 entreprises américaines et européennes : La consolidation des systèmes de stockage reste le besoin n°1 pour près de 80% des participants !
Pour approfondir ce sujet très riche, je vous recommande les 3 vidéos suivantes de la Storage Developper Conference 2020 du SNIA :
- Let’s Manage « NVMe over Fabrics » : https://www.youtube.com/watch?v=AGf6ymj6G7U&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=2
- Shared storage using NVMe Over Fabrics : https://www.youtube.com/watch?v=X7tRIwmFugs&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=10
- Understanding NVMe namespaces : https://www.youtube.com/watch?v=7MYw-0qfpH8&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=14
Storage Class Memory (SCM)
Toujours dans la recherche de plus de performance, la technologie propose aujourd’hui le Storage Class Memory (SCM), qui vient se placer entre la mémoire classique DRAM et le stockage Flash tel que décrit plus haut dans ce document.
Le SCM permet donc de combiner la performance de la mémoire avec la persistance du stockage. L’accès aux données est donc sensiblement plus rapide que sur les disques locaux ou sur le stockage partagé. Globalement le gain est de l’ordre de x10 en lecture et en écriture, avec une durée de vie plus longue que les disques Flash « classiques ».
Le SCM permet par exemple de disposer d’espace « mémoire « beaucoup plus grand à un coût moindre que la DRAM pour des performances proches (ex : SAP HANA).
Ses principaux atouts sont les suivants :
- Temps de réponse plus faible et débit plus élevé que les disques Flash classiques
- Coût moindre que la DRAM
- Accès en temps-réel pour un usage de type mémoire
- Persistance des données contrairement à la mémoire
Le SCM est alors particulièrement séduisant pour la détection de fraude, l’analyse des cyberattaques, les transactions boursières, l’analyse des données en temps réel (IoT), …
A ce jour, la technologie SCM la plus répandue est 3D Xpoint, notamment utilisée par Intel avec sa gamme Optane, avec des modules de 128Go à 512Go, ou Micron Technology. Kioxia (ex Toshiba Memory) ou Samsung sont aussi dans la course avec d’autres solutions.
Les performances atteintes par un seul disque sont tout simplement hallucinantes : latence inférieure à 10 microsecondes, plus de 2,5 millions d’E/S et débit supérieur à 9Go/s en lecture/écriture. !
Les principaux acteurs du marché ont dors et déjà intégré le SCM dans leurs serveurs et leurs baies, comme Dell/EMC, Pure Storage ou HPE, et la liste s’allonge constamment.
Maintenant, le prix du SCM reste encore très élevé par rapport aux disques Flash classiques. C’est donc juste le début de l’histoire. Mais rappelons-nous simplement où en était le disque SSD en 2010 …
Vous avez donc tout le temps pour creuser ce sujet avec 2 vidéos suivantes de la Storage Developper Conference 2020 du SNIA :
- A brief introduction to persistent memory : https://www.youtube.com/watch?v=riZeXrCo43I&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=3
- PMEM file-system in user-space : https://www.youtube.com/watch?v=hJjIHQSDOHI&list=PLH_ag5Km-YUY5M5HFLHsJNDZt35n8vGdD&index=8
Software Defined Storage (SDS)
Après cette immersion dans la technologie, il est temps de reprendre de la hauteur et d’évoquer le Software Defined Storage (SDS).
Comme tous les composants de l’infrastructure, le stockage a lui aussi cédé à la démarche « Software Defined ». En fait, il s’agissait notamment de (re)mettre en lumière l’intelligence du stockage qui a toujours été en très grande partie dans le logiciel, pudiquement appelé pendant des années « microcode ».
Bien évidemment, le matériel contribue grandement au stockage comme nous l’avons vu avec le stockage Flash ou SCM, mais les fonctionnalités comme les clichés, les clones, la déduplication, la compression, la réplication, … sont avant tout une affaire de code !
Mais le SDS, c’est plus que cela. C’est aussi la volonté de banaliser le matériel sous-jacent et d’éviter l’utilisation de composants spécifiques (souvent appelés ASIC). Autrement dit SDS rime souvent avec serveur x86, protocole TCP-IP et disques SSD du marché.
Et cela reste une tendance d’actualité, comme le montre l’évolution récente de la gamme DellEMC ISILON vers PowerScale avec le remplacement des nœuds historiques spécifiques par des serveurs Dell ou l’abandon des cartes spécifiques de gestion de la réduction des données par HPE sur Simplivity au profil d’une solution 100% logicielle !
Le SDS portait cette promesse de mettre à disposition un stockage simple (x86 & IP), économique (« commodités »), évolutif (« Scale-Out ») et universel (fichier / bloc / objet). Très lourde tâche !
Je souhaite ici m’attarder principalement sur le côté universel. L’omniprésence du logiciel devait permettre de tout faire (il suffit simplement de développer !) afin de répondre aux besoins du client avec tout type de stockage : bloc, fichier, objet. Et ce au moindre coût vis-à-vis des baies de stockage
Force est de constater après plusieurs années que nous sommes loin d’avoir atteint ce Graal. Certes il existe des solutions SDS avec une approche stockage universel comme CEPH chez SuSe ou RedHat mais l’adoption reste limitée. Et à ce propos, la décision de RedHat de positionner CEPH comme le stockage d’OpenShift n’a pas été franchement accueilli comme une excellente nouvelle !
En revanche, l’architecture SDS, c-a-d des serveurs avec du stockage local, connectés en général via IP est devenue une référence pour de nombreux usages ciblés : hyperconvergence, NAS scale-out, stockage objet, stockage secondaire, …
En synthèse, oui le SDS est partout aujourd’hui, non il n’est pas devenu le fameux stockage universel dont tout le monde rêve.
Justement il est temps de se pencher sur ces différentes déclinaisons …
Hyperconvergence
Vous devez vous dire, « le pauvre vieux, il ne va pas bien dans sa tête ! », il veut nous parler de l’hyperconvergence, dans un article sur le stockage ?!? Oui, je l’avoue, cela peut paraître étonnant.
En fait, loin de moi l’idée de revenir sur l’histoire, les solutions, les fondamentaux de l’hyperconvergence.
Quoi que …
Je souhaite simplement attirer votre attention sur l’évolution des infrastructures hyperconvergées avec ce que l’on appelle communément sur le marché HCI 2.0.
Les solutions hyperconvergentes se répandent de plus en plus, pour des applications critiques en production, portées par des acteurs majeurs comme VMware et Nutanix, et aussi Cisco ou HPE (voir mon article sur le dernier Forrester Wace HCI 2020).
En revanche, le retour d’expérience des clients montre que leur cas d’usage reste souvent ciblé sur des besoins spécifiques, comme le VDI, le Big Data ou un périmètre Métier précis. Autrement dit l’approche par silo prédomine encore.
En effet, il s’avère compliqué de gérer sur la même plate-forme la diversité des besoins en processeur, mémoire, stockage pour des applications différentes, et une évolutivité importante.
Malgré les progrès réalisés par les solutions, l’universalité de la plate-forme hyperconvergente à grande échelle reste à démontrer, notamment sur le long terme (ex : croissance de la volumétrie, besoins ponctuels de puissance de traitement, …). Seules les plates-formes déployées pour des clients modestes avec moins de 5 nœuds peuvent réellement prétendre à ce statut.
Face à cet obstacle, l’approche HCI 2.0, initialement portée par des acteurs comme Axelio ou Datrium, est en rupture avec le marché de l’hyperconvergence dans le sens où les couches « Compute » et « Storage » sont « de facto » dissociées, afin de pouvoir faire évoluer les ressources de façon totalement indépendantes, afin répondre aux différents besoins.
C’est très différent VMware VSAN, Nutanix ou Simplivity, où la flexibilité passe par des nœuds avec des configurations différentes, voire dédiés au stockage le cas échéant.
Le point important est que cette approche a été adoptée il y a 2 ans environ par NetApp avec son infrastructure dite « désagrégée » sur la base de …. SolidFire OS, acteur historique du stockage Flash ! La boucle est bouclée.
Certes la solution NetApp HCI s’adresse à des configurations déjà importantes avec 4 nœuds au minimum, mais elles disposent d’un ADN intéressant pour une approche universelle, avec la garantie des performances quel que soit le profil de l’application, sur une plate-forme unique.
Allons plus loin.
HCI 2.0 est finalement une étape vers les infrastructures dites « composables » où tous les composants (processeur/mémoire, stockage, réseau) sont mis à disposition pour bâtir le « module » adapté aux besoins du Métier, avec les ressources adéquates, notamment le stockage.
Initialement lancée par Ericsson, ce nouveau type d’infrastructure est aujourd’hui principalement porté par HPE avec Synergy, et des acteurs moins connus comme Liqid ou DriveScale. A suivre …
Stockage Objet
Voilà un thème qui me passionne depuis des années. J’avais la certitude qu’il allait décoller telle une fusée, et devenir le complément unique et universel (encore une fois, un rêve …) du stockage des applications critiques de production.
Et bien non, le stockage Objet n’a pas explosé et aujourd’hui il est très souvent spontanément associé avec S3, aussi bien le protocole que le stockage Object proposé par AWS ! C’est bien mais cela pourrait être tellement plus.
Tout d’abord, le stockage Objet n’est pas voué à un être un simple stockage complémentaire (voire secondaire …). Pour des entreprises, notamment dans le domaine du Media, de la surveillance ou des activités pétrochimiques, il est adapté et pertinent pour supporter les applications « cœur de Métier ».
En effet, la structure même du stockage Objet c-a-d un référentiel plat (Namespace) avec des millions, voire des milliards de « sacs d’octets » plus ou moins grands (de quelques Ko à plusieurs centaines de Go !), avec leurs métadonnées enrichies et un simple identifiant, répond bien mieux aux besoins de ces clients que le système de fichiers classiques ou « même Scale-Out »
Les difficultés rencontrées par les pionniers dans le domaine ont été multiples.
Tout d’abord l’objet le plus répandu chez les clients est le simple fichier, stocké en général sur un NAS. Et le mode d’accès privilégié pour ce fichier sont les protocoles NFS et SMB. Donc tout stockage objet doit avoir une passerelle embarquée simple et efficace pour ces protocoles. Seules les nouvelles applications pouvaient être nativement développées en RestAPI pour un usage direct en mode Objet. Mais cela a fortement restreint les cas d’usage.
Ensuite, beaucoup de solutions étaient « commercialement » viables pour des volumétries de plusieurs centaines de To, voire de l’ordre du Po. Une nouvelle fois, cela concernait qu’un nombre très réduit de clients.
Finalement, la démarche la plus usuelle était de faire adopter le stockage Objet pour la sauvegarde et ensuite de voir comment le réutiliser pour des besoins plus « nobles ».
A ce petit jeu, le stockage Objet a été adopté finalement très lentement par les clients, et pendant ce temps, les solutions basées sur des systèmes de fichiers « Scale-Out » ont proposé de plus en plus souvent une interface S3 afin de capter les nouvelles applications pensées autour de l’Objet tout en étant pertinentes pour les usages classiques avec les fichiers.
Et aujourd’hui les 2 marchés du stockage Objet et du NAS « Scale-Out » (ex : Qumulo) se mélangent, comme le montre par exemple le Magic Quadrant du Gartner « Distributed File Systems and Object Storage » !
Les grands acteurs du stockage ont donc eu le temps de réagir avec des solutions simplement rachetées (ex : IBM COS) ou développées (ex : Dell/EMC ECS, NetApp StorageGrid, PureStorage FlashBlade) souvent sur la base d’une technologie « absorbée » d’une startup.
Et les fournisseurs de Cloud public se sont eux aussi engouffrés dans la brèche afin de proposer un stockage capacitif (plus ou moins) économique, facile d’accès et souple. Sans compter les nouveaux acteurs comme Rubrik ou Cohesity qui proposent des alternatives intéressantes pour l‘évolution de la sauvegarde.
Par conséquent, les « pure players » visibles en France ne sont plus très nombreux, comme Scality et Cloudian, et certains « disparaissent » encore comme OpenIO avec le rachat récent par OVHcloud.
Finalement, à titre personnel, je pense que le rdv prometteur a été en grande partie manqué même si la solution technique est et reste pertinente. Dommage.
Stockage secondaire
Ultime déclinaison du SDS (pour cet article, je précise), avec ou sans d’appliances matérielles, le fameux stockage secondaire.
Tout d’abord, qu’est-ce que le stockage secondaire ? ce n’est pas une technologie particulière. Le stockage secondaire peut être bloc, fichier ou objet. En fait il se définit surtout en regard du stockage primaire. Cela peut paraître évident mais il est bon de le rappeler.
Si le stockage primaire correspond aux données nécessaires pour les applications critiques au fonctionnement même de l’entreprise, le stockage secondaire englobe donc tout le reste, que le périmètre soit technique (ex : sauvegarde) soit fonctionnel (ex : archivage).
Cela ne veut surtout pas dire qu’il n’est pas important. La sauvegarde est incontournable comme l’archivage mais l’entreprise peut fonctionner sans pendant « un certain temps ». En revanche lorsque le système de facturation est en panne, l’horloge de l’argent s’écoule inexorablement …
Bien évidemment, tout ceci doit être nuancé en fonction des entreprises mais les fondamentaux sont bien là.
Le stockage secondaire vise donc à proposer une alternative pour héberger des données a priori moins critiques à moindre coût que le stockage primaire performant, hautement disponible et résilient.
Les premiers acteurs comme Actifio ou Delphix, sont entrés sur ce marché principalement pour optimiser la gestion des nombreuses copies d’une même base de données (jusqu’à 10 chez certains clients !) pour les besoins de développement, d’intégration, de pré-production, d’archivage, …
Ensuite, d’autres pour fournisseurs comme Rubrik ou Cohesity ont proposé une approche très en rupture avec une plate-forme … universelle (encore une fois ! c’est bien l’idée fixe du monde du stockage …) pour gérer la sauvegarde, l’archivage, les copies de bases de données, les fichiers « tièdes », les données analytiques, …
L’offre techniquement séduisante était malheureusement illisible car trop transverse chez les clients avec trop d’équipes impactées.
Heureusement ces nouveaux entrants ont bien compris la leçon, et ils se sont focalisés principalement sur 2 sujets où les optimisations étaient importantes et relativement simples : la sauvegarde et le NAS.
Et voilà pourquoi aujourd’hui Rubrik et Cohesity se sont invités dans le peloton de tête des classements pour les solutions de sauvegarde aux côtés des acteurs historiques comme Veritas, Dell/EMC ou IBM. Et même les solutions plus récentes comme CommVault ou Veeam ont dû réagir, soit avec le rachat d’une technologie adaptée (Hedvig par CommVault), soit par des partenariats (Veeam avec Nutanix Mine).
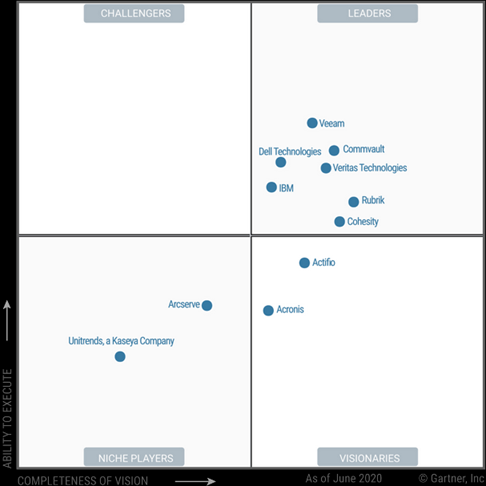
Magic Quadrant for Data Center Backup and Recovery Solutions, July 2020
L’autre cheval de bataille est le serveur de fichiers classique (le bon vieux NAS), surtout en environnement ROBO (agences, usines, …). Quoi de plus simple que de le coupler à l’environnement de sauvegarde au sein d’une plate-forme unique, répliquée automatiquement sur le site principal dans le Datacenter.
Cohesity est une solution particulièrement intéressante sur ce sujet.
A ce titre, la simplicité est un point majeur dans le succès des solutions dites de stockage secondaire. Autant un client est prêt à accepter une certaine complexité pour le stockage primaire car enjeux et les conséquences pour l’entreprise peuvent le justifier (maintenant s’il peut faire simple, il le fera !), autant pour des données considérées comme secondaires c’est hors de question.
Ceci marque la fin de la partie 1.
A très bientôt pour la suite !
Frédéric CHOMETTE, Directeur Solutions