
Vous avez sans doute entendu parler de la vague d’attaques Ransomware contre les ESXi.
Ce type d’attaque vient chiffrer tous les fichiers importants sur vos ESXs : les fichiers de configurations de l’ESXi, mais aussi (et surtout) tous les fichiers de vos VMs (.vmx, .vmdk, -flat.vmdk…)
Si vous êtes touchés par une telle attaque, vos VMs sont probablement toutes inaccessibles et il vous est impossible de vous connecter aux ESXi, que ce soit par le client Web, le SSH ou la console… Il faut alors espérer avoir de bonnes sauvegardes…
Ou bien avoir eu la bonne idée de choisir VMware vSAN comme solution de stockage.
En effet, contrairement à toutes les solutions concurrentes – qui stockent les disques des VMs sous forme de fichiers – vSAN stocke les disques des VMs sous forme d’Objets. Les attaques de type Ransomware actuelles viennent chiffrer des fichiers et ne sont, actuellement, pas programmées pour attaquer des objets. Avec un stockage vSAN, tout n’est peut-être pas perdu.
L’un de nos clients a été touché par une telle attaque et avec l’aide du support VMware nous avons pu retrouver une grande partie des données. Nous allons ici détailler les étapes suivies pour retrouver l’accès à ces données.
Nous ne pouvons affirmer que cela fonctionnera dans votre cas et nous vous invitons évidemment à vous rapprocher du Support VMware pour vous accompagner dans ces étapes…
Voici, dans les grandes lignes, les étapes suivies :

Etape 1 : Réinstaller un ESX et tenter de l’intégrer au cluster
Comme indiqué plus haut, il est impossible de se connecter aux ESXi. De plus, par sécurité, le réseau LAN des ESXs a dû être coupé (pour ne pas propager une éventuelle attaque). Il ne reste donc plus que l’accès « Ecran/Clavier »
Nous allons donc choisir un ESXi cobaye du cluster et le redémarrer. Comme les fichiers de configuration sont eux aussi chiffrés, les 2 « Bootbanks » sont corrompues et l’ESXi ne redémarrera pas. Il faut passer par la case « Réinstallation »
L’idée ici est de s’inspirer de la procédure de VMware permettant à un ESX ayant planté de se reconnecter à un cluster vSAN existant :
- Commencer par réinstaller l’ESXi en respectant la version déjà présente sur les ESXi
- Puis, faire une configuration réseau vSAN minimale.
Les étapes 3, 4 et 5 de la KB sont impossibles dans notre cas :
- Le LAN de l’ESX étant coupé, même si le vCenter est encore accessible, nous n’ajouterons pas l’hôte au vCenter
- Les ESX du cluster sont tous inaccessible, donc pas de connexion SSH possible et l’étape 5 est donc impossible
Nous en sommes donc à l’étape 6 : rejoindre le cluster par la commande
esxcli vsan cluster join -u sub_cluster_UUID
Si vous connaissez ce sub_cluster_id, c’est top.
Sinon, il faut le trouver. Vous pouvez tenter de consulter les logs vmkernels (accessible par la combinaison de touches ALT+F12 tapée en étant connecté sur la console d’un ESX) et de chercher un ID unique visible sur tous les ESXs du cluster…
Après avoir passé la commande sur l’ID que vous pensez être le bon, nous vérifions si l’hôte a réussi à rejoindre le cluster par la commande :
esxcli vsan cluster get
Si cela s’est bien passé, vous devriez avoir un résultat semblable à celui-ci (l’hôte est intégré à un cluster à plusieurs membres) :
[root@monesx1:~] esxcli vsan cluster get Cluster Information Enabled: true Current Local Time: 2023-02-10T11:01:51Z Local Node UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Local Node Type: NORMAL Local Node State: MASTER Local Node Health State: HEALTHY Sub-Cluster Master UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Sub-Cluster Backup UUID: 63dd24fb-f098-7dd8-d108-78ac440739b8 Sub-Cluster UUID: 5229207b-c00a-242f-3e79-ac063a9c26fb Sub-Cluster Membership Entry Revision: 1 Sub-Cluster Member Count: 4 Sub-Cluster Member UUIDs: 63dd24fb-f098-7dd8-d108-78ac440739b8, 63dd24b1-d4ae-9a6e-2d27-78ac44072152, 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76, 63dd126c-6aca-ebf8-a3be-78ac44073886 Sub-Cluster Member HostNames: monesx4, monesx3, monesx1, monesx2 Sub-Cluster Membership UUID: 9bc1de63-6484-6576-c270-78ac4406ef76 Unicast Mode Enabled: true Maintenance Mode State: OFF Config Generation: cccca5b8-cf79-4ff3-a108-432b6fc0a371 7 2023-02-05T08:53:21.872 Mode: REGULAR
Vous pouvez passer à l’Etape 3. S’il n’y a qu’un seul membre, nous continuons par l’étape 2.
Etape 2 : Reconstruire le Cluster
Si vous êtes ici, c’est que l’ID n’était pas le bon. L’hôte se retrouve tout seul dans un cluster et la liste des « voisins » Unicast est probablement vide :
[root@monesx1:~] esxcli vsan cluster get Cluster Information Enabled: true Current Local Time: 2023-02-10T11:01:51Z Local Node UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Local Node Type: NORMAL Local Node State: MASTER Local Node Health State: HEALTHY Sub-Cluster Master UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Sub-Cluster Backup UUID: Sub-Cluster UUID: 5229207b-c00a-242f-3e79-ac063a9c26fb Sub-Cluster Membership Entry Revision: 0 Sub-Cluster Member Count: 1 Sub-Cluster Member UUIDs: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Sub-Cluster Member HostNames: monesx1 Sub-Cluster Membership UUID: 9bc1de63-6484-6576-c270-78ac4406ef76 Unicast Mode Enabled: true Maintenance Mode State: OFF Config Generation: None 0 0.0 Mode: REGULAR [root@monesx1:~] esxcli vsan cluster unicastagent list [root@monesx1:~]
Nous allons maintenant vérifier si l’hôte réussi à « voir » qu’il possède des disques « taggués » vSAN :
[root@monesx1:~] esxcli vsan debug disk list | grep -i cmmds In Cmmds: true In Cmmds: true In Cmmds: true In Cmmds: true In Cmmds: true
Dans mon cas, j’ai bien mes 5 disques (1 disque de cache et 4 disques capacitifs). C’est positif, nous avançons. Nous vérifions maintenant qu’il détecte bien les objets vSAN :
[root@monesx1:~] esxcli vsan debug object health summary get Health Status Number Of Objects --------------------------------------------------------- ----------------- remoteAccessible 0 inaccessible 161 reduced-availability-with-no-rebuild 0 reduced-availability-with-no-rebuild-delay-timer 0 reducedavailabilitywithpolicypending 0 reducedavailabilitywithpolicypendingfailed 0 reduced-availability-with-active-rebuild 0 reducedavailabilitywithpausedrebuild 0 data-move 0 nonavailability-related-reconfig 0 nonavailabilityrelatedincompliancewithpolicypending 0 nonavailabilityrelatedincompliancewithpolicypendingfailed 0 nonavailability-related-incompliance 0 nonavailabilityrelatedincompliancewithpausedrebuild 0 healthy 0
Les objets sont présents mais ils sont inaccessibles. C’est attendu, puisque l’hôte est seul membre du cluster. Nous pouvons continuer à avancer.
Il faut maintenant réinstaller, un à un, les autres membres du cluster, et donc, comme pour le premier ESX :
- Réinstaller l’ESX à la même version
- Appliquer une configuration réseau vSAN minimale
Une fois les autres membres du cluster réinstallés, nous allons les ajouter au cluster créé par notre premier ESX en exécutant la commande : esxcli vsan cluster join -u sub_cluster_UUID (l’UUID à utiliser ici est le même que celui utilisé pour le premier ESX)
Puis, nous recréons les « voisins » unicast en s’aidant de la KB VMware 2150303 et en respectant le fait qu’un hôte ne doit pas être voisin de lui-même :
- L’hôte 1 doit avoir les hôtes 2, 3 et 4 dans sa liste
- L’hôte 2 doit avoir les hôtes 1, 3 et 4 dans sa liste
- …
C’est la commande :
esxcli vsan cluster unicastagent add -t node -u <Host_UUID> -U true -a <Host_VSAN_IP> -p 12321
qui permet de recréer cette liste.
Si tout s’est bien passé, vous devriez avoir les 4 hôtes membres d’un seul et même cluster. Et les objets doivent maintenant être listés comme « Healthy »
[root@monesx1:~] esxcli vsan cluster get Cluster Information Enabled: true Current Local Time: 2023-02-10T11:01:51Z Local Node UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Local Node Type: NORMAL Local Node State: MASTER Local Node Health State: HEALTHY Sub-Cluster Master UUID: 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76 Sub-Cluster Backup UUID: 63dd24fb-f098-7dd8-d108-78ac440739b8 Sub-Cluster UUID: 5229207b-c00a-242f-3e79-ac063a9c26fb Sub-Cluster Membership Entry Revision: 1 Sub-Cluster Member Count: 4 Sub-Cluster Member UUIDs: 63dd24fb-f098-7dd8-d108-78ac440739b8, 63dd24b1-d4ae-9a6e-2d27-78ac44072152, 63dd0bfc-b2d1-ff74-f1f7-78ac4406ef76, 63dd126c-6aca-ebf8-a3be-78ac44073886 Sub-Cluster Member HostNames: monesx4, monesx3, monesx1, monesx2 Sub-Cluster Membership UUID: 9bc1de63-6484-6576-c270-78ac4406ef76 Unicast Mode Enabled: true Maintenance Mode State: OFF Config Generation: cccca5b8-cf79-4ff3-a108-432b6fc0a371 7 2023-02-05T08:53:21.872 Mode: REGULAR [root@monesx1:~] esxcli vsan debug object health summary get Health Status Number Of Objects --------------------------------------------------------- ----------------- remoteAccessible 0 inaccessible 0 reduced-availability-with-no-rebuild 0 reduced-availability-with-no-rebuild-delay-timer 0 reducedavailabilitywithpolicypending 0 reducedavailabilitywithpolicypendingfailed 0 reduced-availability-with-active-rebuild 0 reducedavailabilitywithpausedrebuild 0 data-move 0 nonavailability-related-reconfig 0 nonavailabilityrelatedincompliancewithpolicypending 0 nonavailabilityrelatedincompliancewithpolicypendingfailed 0 nonavailability-related-incompliance 0 nonavailabilityrelatedincompliancewithpausedrebuild 0 healthy
Etape 3 : Constater les dégâts
Lorsque le cluster est reconstitué et que les objets sont sains, il est temps d’aller voir l’état des VMs :
[root@monesx1:~] ls -l /vmfs/volumes/vsan:5229207bc00a242f-3e79ac063a9c26fb/MA-VM4/ total 159784 -rw-r--r-- 1 root root 624 Dec 26 14:45 MA-VM4-2dd32c7d.hlog.royal_u -rw------- 1 root root 544 Dec 26 14:45 MA-VM4-aux.xml.royal_u -rw------- 1 root root 4916240 Dec 26 14:45 MA-VM4-ctk.vmdk.royal_u -rw------- 1 root root 9216 Dec 26 14:45 MA-VM4.nvram.royal_u -rw------- 1 root root 1216 Dec 26 14:45 MA-VM4.vmdk.royal_u -rw-r--r-- 1 root root 576 Dec 26 14:45 MA-VM4.vmsd.royal_u -rwxr-xr-x 1 root root 4368 Dec 26 14:45 MA-VM4.vmx.royal_u -rw------- 1 root root 4464 Dec 26 14:45 MA-VM4.vmxf.royal_u -rw-r--r-- 1 root root 1473 Feb 2 15:45 readme -rw-r--r-- 1 root root 3386384 Dec 26 14:45 vmware-19.log.royal_u -rw-r--r-- 1 root root 11416208 Dec 26 14:45 vmware-20.log.royal_u -rw-r--r-- 1 root root 14268976 Dec 26 14:45 vmware-21.log.royal_u -rw-r--r-- 1 root root 287392 Dec 26 14:45 vmware-22.log.royal_u -rw-r--r-- 1 root root 8368448 Dec 26 14:45 vmware-23.log.royal_u -rw-r--r-- 1 root root 5305280 Dec 26 14:45 vmware-24.log.royal_u -rw-r--r-- 1 root root 20798720 Dec 26 14:45 vmware.log.royal_u -rw------- 1 root root 89129488 Dec 26 14:45 vmx-MA-VM4-585bd2db439e8e507d7ef699dd2c2e4e8cf8e074-1.vswp.royal_u
Tous les fichiers ont une extension « .royal_u »… Nous sommes victimes de Royal Ransomware. Chaque dossier contien maintenant aussi un fichier readme contenant les instructions de rançons :
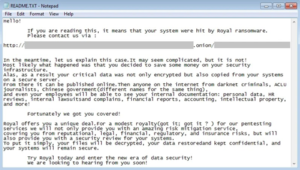
Malheureusement, il n’existe pas encore d’outils de déchiffrement pour ce Ransomware… Donc nous continuons avec vSAN.
A ce stade, il est plus aisé de travailler en SSH, voire avec un vCenter. Nous allons donc activer le LAN des ESXs. Si le premier « join cluster » de l’étape 1 a été concluant, alors certains ESXs membres du cluster n’ont pas été réinstallés et peuvent potentiellement toujours être infectés. Il est alors plus prudent de tous les réinstaller afin d’effacer toute trace du virus.
Etape 4 : Retrouver le contenu des disques
Comme on l’a vu juste au-dessus, le fichier descripteur du disque (.vmdk) est chiffré. Il est n’est donc pas accessible. Nous avons donc besoin de le recréer. Mais on a besoin de quelques infos pour cela.
Identifier les objets vSAN Accessible mais non associés
Si vous ne souhaitez pas réinstaller un vCenter, vous pouvez utiliser la commande esxcli vsan debug object list –all pour remonter les informations nécessaires. Cependant, vCenter offre l’accès a rvc et facilite l’identification des objets à récupérer.
Ainsi, de mon côté, j’ai préféré réinstaller un vCenter en dehors de vSAN. J’ai créé un nouveau cluster avec vSAN activé et j’ai intégré mes 4 nœuds. Je peux donc utiliser les commandes rvc pour continuer le debug. Et je me suis donc aidé de la KB VMware permettant d’identifier les objets non associés.
#La commande suivante fait un rapport de tous les objets et liste donc tous les objets « Unassociated » > vsan.obj_status_report -t <pathToCluster> 2023-02-04 10:53:13 +0000: Querying all VMs on vSAN ... 2023-02-04 10:53:13 +0000: Querying DOM_OBJECT in the system from monesx1 ... 2023-02-04 10:53:13 +0000: Querying DOM_OBJECT in the system from monesx2 ... 2023-02-04 10:53:13 +0000: Querying DOM_OBJECT in the system from monesx3 ... 2023-02-04 10:53:13 +0000: Querying DOM_OBJECT in the system from monesx4 ... [...] +--------------------------------------------+---------+----------+ | Unassociated objects | 37 | | | [...] | | | | cf8dd75f-cc5e-6139-3851-78ac440739b8 | | 3/3 | | 19e3d95f-06c7-3a55-42cd-78ac44073886 | | 3/3 | | [...] | | | +--------------------------------------------+---------+----------+
L’idée est ensuite de copier toutes les lignes contenant les UUID non associés et de créer un nouveau fichier « input.txt » puis de lancer une commande permettant de ne garder que ces UUID.
root@vcenter [ /tmp ]# cat /tmp/input.txt | awk '{print $2}' |awk '/^'.'/ {printf "%s ",$0} END {print ""}' > /tmp/output.txt
Le fichier output.txt contient alors tous les objets non associés. Il nous faut maintenant les identifier. Pour cela, nous retournons sur rvc et nous passons cette liste en paramètre de la commande vsan.object_info. (ici, je me limite aux 2 objets pris en exemple, mais il est tout à fait possible de passer tous les UUID des objets remontés comme non associés par la commande précédente) :
> vsan.object_info localhost/DC/computers/vSAN/ cf8dd75f-cc5e-6139-3851-78ac440739b8 19e3d95f-06c7-3a55-42cd-78ac44073886
Je vous conseille alors de mettre le résultat de cette commande dans un fichier texte que vous conserverez précieusement. Ce fichier contient toutes les informations nécessaires vous permettant de retrouver l’accès aux disques de vos VMs. Voici un extrait de son contenu :
[...] DOM Object: cf8dd75f-cc5e-6139-3851-78ac440739b8 (v15, owner: monesx1.virtu.local, proxy owner: None, policy: stripeWidth = 1, cacheReservation = 0, proportionalCapacity = [0, 100], hostFailuresToTolerate = 1, forceProvisioning = 0, spbmProfileId = 4daa9a65-6716-4c5d-88ea-23a0d6f5b6e3, spbmProfileGenerationNumber = 0, objectVersion = 15, replicaPreference = Performance, iopsLimit = 0, checksumDisabled = 0, CSN = 20994, SCSN = 20919, spbmProfileName = vSAN - Raid1) RAID_1 Component: dd65df63-247a-5c5c-12bb-78ac440739b8 (state: ACTIVE (5), host: monesx3.virtu.local, capacity: naa.500a075129964464, cache: naa.58ce38ee210f0705, votes: 1, usage: 1.0 GB, proxy component: false) Component: cf9adf63-4c7a-69f3-1eac-78ac440739b8 (state: ACTIVE (5), host: monesx2.virtu.local, capacity: naa.500a075129964490, cache: naa.58ce38ee2100fa85, votes: 1, usage: 1.0 GB, proxy component: false) Witness: e2d0de63-3811-94b1-137f-78ac440739b8 (state: ACTIVE (5), host: monesx1.virtu.local, capacity: naa.500a075129963822, cache: naa.58ce38ee210f06f1, votes: 1, usage: 0.0 GB, proxy component: false) Extended attributes: Address space: 273804165120B (255.00 GB) Object class: vmnamespace Object path: /vmfs/volumes/vsan:5229207bc00a242f-3e79ac063a9c26fb/MA-VM4 Object capabilities: NONE DOM Object: 19e3d95f-06c7-3a55-42cd-78ac44073886 (v15, owner: monesx1.virtu.local, proxy owner: None, policy: stripeWidth = 1, cacheReservation = 0, proportionalCapacity = 0, hostFailuresToTolerate = 1, forceProvisioning = 0, spbmProfileId = 4daa9a65-6716-4c5d-88ea-23a0d6f5b6e3, spbmProfileGenerationNumber = 0, objectVersion = 15, replicaPreference = Performance, iopsLimit = 0, checksumDisabled = 0, CSN = 21247, SCSN = 21188, spbmProfileName = vSAN - Raid1) RAID_1 Component: 5cd1df63-5617-16d5-ef1c-78ac4406ef76 (state: ACTIVE (5), host: monesx3.virtu.local, capacity: naa.500a075129964107, cache: naa.58ce38ee210f0705, votes: 1, usage: 60.0 GB, proxy component: false) Component: bfd8df63-dc23-b8d8-bffd-78ac4406ef76 (state: ACTIVE (5), host: monesx4.virtu.local, capacity: naa.500a0751299641e7, cache: naa.58ce38ee210efa11, votes: 1, usage: 60.0 GB, proxy component: false) Witness: 5cd1df63-b85b-18d5-4891-78ac4406ef76 (state: ACTIVE (5), host: monesx1.virtu.local, capacity: naa.500a075129964230, cache: naa.58ce38ee210f06f1, votes: 1, usage: 0.0 GB, proxy component: false) Extended attributes: Address space: 161061273600B (150.00 GB) Object class: vdisk Object path: /vmfs/volumes/vsan:5229207bc00a242f-3e79ac063a9c26fb/cf8dd75f-cc5e-6139-3851-78ac440739b8/MA-VM4.vmdk Object capabilities: NONE [...]
Il y a deux types d’objets remontés par cette dernière commande :
- Les objets de type Namespace à C’est le « dossier » contenant les fichiers de la VM
- Les objets de type vDisk à C’est le disque de la VM
Pour ces 2 types d’objets, on identifie facilement la VM concernée en lisant la ligne Object Path.
Dans notre cas, nous souhaitons retrouver l’accès aux disques. Nous allons donc travailler uniquement sur les objets vDisk et nous notons les informations suivantes :
- UUID de l’objet : Dans mon cas 19e3d95f-06c7-3a55-42cd-78ac44073886
- Taille du disque : Dans mon cas 150.00 GB
Créer un nouveau disque
Je vous conseille ici de créer une nouvelle VM vierge sur laquelle vous remonterez les disques récupérés. Cela évitera de démarrer une VM potentiellement infectée.
Dans cette étape, nous créons un nouveau disque d’une taille identique au disque source (ici, 150Go) puis nous modifions le descripteur pour pointer vers l’objet vSAN repéré à l’étape précédente.
En effet, dans le fichier descripteur du nouveau disque (.vmdk), la partie « Extent description » indique l’UUID de l’objet concerné par le descripteur. Nous modifions ainsi la ligne pour indiquer l’emplacement de l’objet du disque que nous voulons récupérer :
#Avant Modification : [root@monesx01:/vmfs/volumes/vsan:523011e791d2eabf-6a83d7de246fbb48/b5b5eb63-1a84-cd91-5f17-0050568287d1] cat Recup-VM_1.vmdk [...] # Extent description RW 314572800 VMFS "vsan://5229207bc00a242f-3e79ac063a9c26fb/c7b5eb63-d70a-5ee6-dd6f-0050568287d1" [...] #Après modification : [root@monesx01:/vmfs/volumes/vsan:523011e791d2eabf-6a83d7de246fbb48/b5b5eb63-1a84-cd91-5f17-0050568287d1] cat Recup-VM_1.vmdk [...] # Extent description RW 314572800 VMFS "vsan://5229207bc00a242f-3e79ac063a9c26fb/19e3d95f-06c7-3a55-42cd-78ac44073886" [...]
Il ne reste plus qu’à « Recharger » la VM :
[root@monesx01:~] vim-cmd vmsvc/getallvms Vmid Name File Guest OS Version Annotation 1 Recup-VM [vsanDatastore] b5b5eb63-1a84-cd91-5f17-0050568287d1/Recup-VM.vmx windows2019srv_64Guest vmx-19 [root@monesx01:~] vim-cmd vmsvc/reload 1
Et à contrôler dans la VM si les données sont accessibles :
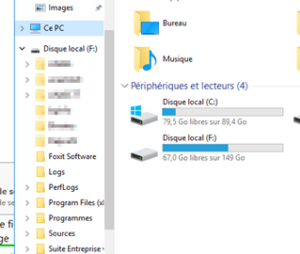
Conclusion
Cet article décrit la procédure à suivre pour retrouver l’accès aux données contenues dans vSAN avant l’attaque. En revanche, si les VMs avaient aussi été chiffrées au niveau OS, alors les données ne seront malheureusement pas accessibles. Et alors, de bonnes sauvegardes et une bonne solution de PRA sera la seule protection à ce type d’attaque.
Par ailleurs, il est important de noter qu’en modifiant le descripteur des disques créés temporairement, vous rendrez l’objet « vdisk » temporaire associé « Non associés » du point de vue vSAN. Ainsi, une fois la donnée remontée, nous vous conseillons de la sortir de vSAN (par une sauvegarde et/ou un Storage vMotion) afin de pouvoir re-créer proprement le cluster vSAN lorsque les opérations de récupérations seront terminées.
Enfin, encore une fois, cette procédure a fonctionné dans notre cas mais nous ne pouvons pas garantir que cela fonctionnera pour votre cas. Et nous vous invitons évidemment à contacter Metanext et/ou le support VMware pour vous accompagner dans toutes ces démarches.
